Voraussetzung für die Anwendung von t-Test und F-Test im klassischen Regressionsmodell ist eine Normalverteilung der Residuen. Diese Normalverteilungsannahme ist zur Kleinst-Quadrate-Schätzung der Koeffizienten des linearen Regressionsmodells an sich nicht erforderlich. Wenn diese Annahme jedoch erfüllt ist, ist der Kleinst-Quadrate-Schätzer identisch mit dem Größte-Dichte-Schätzer (=Maximum-Likelihood-Schätzer).[1]
Sowohl Backhaus[2] als auch Kockläuner[3] empfehlen zur Überprüfung der Normalverteilungsannahme die Überprüfung anhand von graphischen Hilfsmitteln. Zu diesem Zweck bieten sich vor allem zwei graphische Unterstützungen an. An erster Stelle steht hier das Histogramm der standartisierten Residuenwerte, das über den Regressionsbefehl von SPSS zu erreichen ist. Dabei wird die Verteilung der Residuenwerte einer stilisierten Normalverteilung gegenübergestellt. Auf der anderen Seite stellt SPSS unter dem Regressionsbefehl den Normal Probability (P-P) Plot zur Verfügung. Dieses Diagramm entsteht dadurch, daß die vorliegenden standartisierten Residuenwerte der Größe nach geordnet werden, um auf der vertikalen Achse die zugehörigen Werte ihrer empirischen Verteilungsfunktion abtragen zu können. Auf der horizontalen Achse werden diesen die Funktionswerte der standartisierten Normalverteilung gegenübergestellt. Dies ist die empirische Verteilungsfunktion der Erwartungswerte von n Ordnungsstatistiken. Letztere ergeben sich aus der größenmäßigen Anordnung von n unabhängigen standartisierten normalverteilten Zufallsvariablen. Prozentpunkte deren Verteilung liefern die angesprochenen Erwartungswerte. Normal Probability Plots sind dann wie folgt zu interpretieren: Nach Konstruktion der Achsen sind alle Koordinatenpaare immer dann auf der stilisierten Gerade liegend zu erwarten, wenn die eingehenden Beobachtungen Realisationen unabhängig standardisierter normalverteilter Zufallsvariablen darstellen.[4]
Grundsätzlich ist davon auszugehen, daß die Normalverteilungsannahme in der Regel verletzt sein wird, weil Normalverteilungen in der Realität kaum vorkommen. Der zentrale Grenzwertsatz liefert aber die Argumentation dafür, daß die Störgrößen im Regressionsmodell wenigstens als näherungsweise normalverteilt gelten können.[5] In diesem Zusammenhang ist jedoch die Gefahr der Supernormalität zu beachten. Kurz zusammengefaßt ist darunter zu verstehen, daß bei großen Stichproben die Residuenwerte als gewichtete Summe der Störgrößen auch dann annähernd normalverteilt sein können, wenn die Störgrößen nicht einer Normalverteilung genügen. Daher läßt die Verteilung der Residuen oft nicht die Verletzung der Normalverteilungsannahme erkennen. Hinzu kommt in dieser Untersuchung, daß die Konstrukte aus mehreren Items gebildet werden, was die Nicht-Normalität weiter verschleiert. „Trotzdem bleibt diese Verteilung das einzige Instrument zur Überprüfung der Normalverteilungsannahme, die für alle n Störgrößen ui und damit n einzelne Verteilungen gelten soll.“[6] Auf die weiteren statistischen Bedingungen für die Überprüfung der Normalverteilungsannahme wird an dieser Stelle nicht eingegangen, da diese statistischen Feinheiten nicht Thema einer inhaltlichen Arbeit sein können und den Umfang der Arbeit sprengen würden. Der interessierte Leser sei auf Kockläuner[7] verwiesen. Nur soviel soll hier angemerkt werden: Für die Überprüfung der Normalitätsannahme werden die intern studentisierten Residuen betrachtet, um konstante Varianzen sicherzustellen[8]. Außerdem sollte die Normalitätsbedingung nach Kockläuner die zuletzt zu überprüfende Bedingung sein. Dies hat den Vorteil, daß nicht von n einzelnen Verteilungen, also für jede einzelne Störgröße eine, ausgegangen werden muß, zu denen jeweils nur ein Residuenwert zur Verfügung steht, sondern von einem Verteilungsmodell, zu dessen Überprüfung n Residuenwerte vorliegen.[9]
Die Überprüfung der graphischen Darstellungen führte zu folgenden Ergebnissen: Weitgehend lassen die Normal Probability Plots und vor allem die Histogramme eine relativ gute Anpassung an die Normalverteilung erkennen. Stärkere Abweichungen sind vor allem bei der 3. Regression und männlichem Geschlecht und bei der 5. Regression und weiblichem Geschlecht zu erkennen. Die Graphiken sind nicht in dieser Arbeit abgedruckt, können jedoch mit Hilfe der Syntax auf der beigefügten Diskette problemlos dargestellt werden.
Zur Überprüfung der Residuen auf Normalverteilung, soll zusätzlich der Kolmogorov-Smirnov-Anpassungstest durchgeführt werden. Dieser ist für kleine Stichproben besser geeignet als der 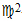 -Test, da letzterer nur approximativ arbeitet.[10] Im Falle eines Ablehnens der Normalverteilungsannahme durch diesen, kann im Anschluß noch eine weitere Verteilungsüberprüfung über Schiefe und Exzeß durchgeführt werden.
-Test, da letzterer nur approximativ arbeitet.[10] Im Falle eines Ablehnens der Normalverteilungsannahme durch diesen, kann im Anschluß noch eine weitere Verteilungsüberprüfung über Schiefe und Exzeß durchgeführt werden.
Die H0 des Kolmogoroff- Smirnov-Anpassungstest lautet, daß die empirisch ermittelte Verteilung gleich der Normalverteilung ist. Die Alternativhypothese lautet, daß sich die beiden Verteilungen für mindestens einen Wert der unabhängigen Variable unterscheiden. Die Hypothese H0 wird nun zum Niveau 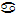 verworfen, wenn Dn multipliziert mit der Wurzel aus der Anzahl der Beobachtungen, größer oder gleich dem aus der Tabelle[11] zu entnehmenden kritischen Wert ist. „Die Größe Dn gibt den größten vertikalen Abstand zwischen hypothetischer und empirischer Verteilungsfunktion an.“[12] Nun ist das Signifikanzniveau zu bestimmen. Üblicherweise wird ein Signifikanzniveau von 1% oder 5% gewählt. An dieser Stelle ist zu beachten, daß es hier darum geht, die Normalverteilungsannahme zu überprüfen und dabei den
verworfen, wenn Dn multipliziert mit der Wurzel aus der Anzahl der Beobachtungen, größer oder gleich dem aus der Tabelle[11] zu entnehmenden kritischen Wert ist. „Die Größe Dn gibt den größten vertikalen Abstand zwischen hypothetischer und empirischer Verteilungsfunktion an.“[12] Nun ist das Signifikanzniveau zu bestimmen. Üblicherweise wird ein Signifikanzniveau von 1% oder 5% gewählt. An dieser Stelle ist zu beachten, daß es hier darum geht, die Normalverteilungsannahme zu überprüfen und dabei den 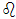 -Fehler, das heißt eine fälschliche Beibehaltung der Nullhypothese zu minimieren. Da sich der -Fehler aus 1- -Fehler berechnet, erscheint es sinnvoll, das Signifikanzniveau an dieser Stelle höher anzusetzen. Im Rahmen der dieser Arbeit wird deshalb ein Signifikanzniveau von 10% zur Ablehnung der Normalverteilungsannahme angesetzt.
-Fehler, das heißt eine fälschliche Beibehaltung der Nullhypothese zu minimieren. Da sich der -Fehler aus 1- -Fehler berechnet, erscheint es sinnvoll, das Signifikanzniveau an dieser Stelle höher anzusetzen. Im Rahmen der dieser Arbeit wird deshalb ein Signifikanzniveau von 10% zur Ablehnung der Normalverteilungsannahme angesetzt.
|
|
weiblich
|
|
männlich
|
|
|
Regression
|
K-S-z
|
Signif.-Niveau
|
K-S-z
|
Signif.-Niveau
|
|
1.a
|
1.1021 |
.1761
|
0.8518 |
.4626
|
|
1.b
|
0.4965 |
.9662
|
0.6876 |
.7317
|
|
2.a
|
0.8341 |
.4898
|
1.0320 |
.2373
|
|
2.b
|
1.0907 |
.1851
|
0.7863 |
.5666
|
|
3.
|
1.0867 |
.1884
|
1.1211 |
.1618
|
|
4.
|
0.7999 |
.5444
|
0.7258 |
.6680
|
|
5.
|
1.0018 |
.2681
|
0.6126 |
.8472
|
|
6.
|
0.9536 |
.3230
|
0.7569 |
.6156
|
Tab. 3 (Kolmogoroff-Smirnov-Test-Wert)
Für sämtliche Regressionen liegen die Kolmogoroff-Smirnov-z-Prüfgrößen und die entsprechenden Signifikanzniveaus über dem geforderten Mindestmaß[13]. Kritisch sind vor allem die Kolmogoroff-Smirnov-z-Prüfgrößen für die Regression 1.a (weiblich), die Regression 5. (weiblich), da hier ja nur 38 Werte in die Untersuchung eingehen und Regression 3. (männlich). Die Normalverteilungsannahme für die Residuenwerte wird trotzdem für alle Regressionen als bestätigt angesehen. Auch das dritte und fünfte Regressionsmodell werden weiter verfolgt, auch wenn vor allem bei dem dritten Modell die Werte auf eine schlechte Erfüllung der Normalverteilungsannahme hindeuten.
[1] vgl.: Gruber, Josef, (1982), S. 58
[2] vgl.: Backhaus, K.; Erichson, B.; Plinke, W.; Weiber, R., (1994), S. 32
[3] vgl: Kockläuner, Gerhard, (1988), S. 58 ff
[4] vgl.: Kockläuner, Gerhard, (1988), S. 58 ff
[5] vgl.: Hartung, J., (1982), S. 122
[6] Kockläuner, Gerhard, (1988), S. 73
[7] Kockläuner, Gerhard, (1988), S. 60-76
[8] vgl.: Kockläuner, Gerhard, (1988), S. 63
[9] Kockläuner, Gerhard, (1988), S. 73
[10] vgl.: Hartung, J., (1982), S. 183
[11] vgl.: Hartung; J. (1982), S. 184
[12] Hartung; J. (1982), S. 184
[13] vgl.: Hartung; J. (1982), S. 184