Der Aussage von Jacoby folgend – „From a philosophy of science perspective, attempts to study and understand a given phenomenon are generally enhanced if one also studies the opposite or negative case.“[1] – erscheint es sinnvoll, sich auch über die Hintergründe von Markenwechsel Gedanken zu machen.
Bei einer Kaufentscheidung gibt es immer genau zwei Alternativen: Die gleiche Marke wiederkaufen oder eine neue Marke ausprobieren. (Die Fälle, bei denen zum ersten Male ein Produkt aus dieser Kategorie ausprobiert wird oder ganz auf einen Kauf verzichtet wird, bleiben ausgeklammert.) Markenwechsel liegt immer dann vor, wenn eine Kaufentscheidung getroffen wird und nicht die gleiche Marke wie beim vorigen Male gekauft wird. Da, wie im Rahmen der Definition von Markentreue schon ausgeführt wurde, die Möglichkeit der Multi-Loyalität ausgeschlossen ist, ist der Kauf einer anderen Marke auf jeden Fall als Markenwechsel zu interpretieren.
Wenn wir später von der Wiederkaufwahrscheinlichkeit sprechen, dann meinen wir damit die Wahrscheinlichkeit einer Kaufentscheidung zugunsten der aktuellen Marke. Die dazu komplementäre Wahrscheinlichkeit ist die des Markenwechsels. Sowohl die Markentreue als auch der Markenwechsel sind Verhaltensweisen und keine Zustände. Beide werden nur in der Entscheidungssituation deutlich. Zwischen den Entscheidungssituationen ist man teilweise irrtümlich versucht, von Markentreue zu sprechen. Dieser Eindruck hängt jedoch damit zusammen, daß es sich bei einer Folge von Kaufentscheidungen nicht um einen marginalen Prozeß handelt. Nicht in jedem Augenblick hat die Einstellung zu der Marke eine Möglichkeit, sich zu manifestieren. Das heißt, es ist möglich, daß sich kurz nach einer markentreuen Kaufentscheidung die Einstellung zu der Marke ändert, so daß bei der nächsten Entscheidung ein Markenwechsel ansteht. In dieser Situation wird ein markentreues Verhalten nach außen sichtbar, während die Einstellung diesem eigentlich entgegengesetzt ist. So wird verständlich, daß es oft besser ist, von der markentreuen Einstellung zu sprechen statt von einem markentreuen Verhalten. Oft ist ein Markenwechsel nicht nur eine einzelne Aktion, sondern charakterisiert einen ganzen Zeitraum. Dieses Verhalten konnte vor allem von Wierenga nachgewiesen werden. Im Rahmen seiner „pool-size“-Untersuchung stellt er fest, daß ein Wechsel von einer Marke zu einer anderen, die, wie die erste dann auch, über einen längeren Zeitraum immer wieder gekauft wird, nicht spontan geschieht. Vielmehr ist zu beobachten, daß die meisten untersuchten Haushalte in der Periode zwischen der Markentreue zu der einen und der anderen Marke verschiedene Marken ausprobieren, um dann letztendlich bei der ausgewählten zu bleiben.[2] Ob die Einstellung zum Markenwechsel eine eigenständige Einstellung ist oder nur die Umkehrung der markentreuen Einstellung, wird im weiteren Verlauf der Arbeit ausführlich diskutiert werden.
Das Verhalten in Kaufsituationen ist vermutlich nicht angeboren, sondern weitgehend gelerntes Verhalten. Dabei spielen sowohl kognitiv, als auch behavioristisch zu erklärende Vorgänge eine Rolle. Im weiteren sind die Kaufentscheidungen für verschiedene Marken die Operanten. Das heißt, die Entscheidung für eine Marke erfolgt zunächst rein zufällig, da der Konsument noch keine Präferenzen einzelnen Marken gegenüber hat.[1] Der Stimulus besteht dann in der Befriedigung von Bedürfnissen und damit verbunden der Erfüllung von Zielvorstellungen.
Im vorigen Abschnitt wurde dargestellt, in welchen Bereichen Motive bestehen, die von der Marke befriedigt werden könnten.
An dieser Stelle ist es notwendig, nochmals auf die funktionellen Eigenschaften der Marke einzugehen.
Die Zielvorstellungen, die mit dem Kauf eines Produktes verbunden sind, richten sich auf die funktionellen Eigenschaften des Produkts. Diese funktionelle Leistungsfähigkeit des Produkts muß sich nicht nur auf materielle Eigenschaften beschränken, sondern umfaßt auch erwartete Prestigewerte der Marke und andere immaterielle Eigenschaften. Ein direkter Zusammenhang besteht zwischen der Erfüllung der funktionellen Anforderungen und den Risiken, die dem Konsumenten drohen, wenn diese Anforderungen nicht erfüllt werden. Dieser Zusammenhang ist ein Ursache-Wirkungs-Zusammenhang. Die Ursache ist die nicht erfüllte funktionelle Anforderung. Die Wirkung besteht in den sich aus diesem Mangel ergebenden Schäden.
Wenn von den funktionellen Eigenschaften und der aus ihnen direkt abgeleiteten Verstärkung abstrahiert wird, hat die Marke jeweils zwei Potentiale, vor der Kaufentscheidung entweder verstärkend oder aversiv zu wirken.
Auf der einen Seite steht die bestrafende Eigenschaft des Risikopotentials, auf der anderen Seite die belohnende Eigenschaft des Abwechslungspotentials. Der hier verwendete Potentialbegriff ist aus der Terminologie von Berlyne[2] entnommen und wird schon an dieser Stelle verwendet, um später den Zusammenhang mit den Theorien des Such- und Entdeckungsverhaltens besser verdeutlichen zu können. Berlyne unterscheidet in seinem Buch nicht nach verschiedenen Potentialen, sondern spricht nur von einem Aktivierungspotential, daß auf sogenannte „collative variables“ zurückzuführen ist. Unter diesem Begriff faßt er allerdings sowohl Fähigkeiten der Marke, das Abwechslungsbedürfnis zu befriedigen, als auch Gefahren, die durch die Marke drohen, zusammen. Das Aktivierungsotential eines Stimulus besteht deshalb in der vom Konsumenten wahrgenommenen Fähigkeit, zum einen die Neugier zu befriedigen und zum anderen Risiken zu begründen. Für das weitere Vorgehen soll das Aktivierungspotential von Berlyne in die zwei Bereiche Abwechslungspotential und Risikopotential unterteilt werden.
Damit ergeben sich die folgenden Verstärkereigenschaften der Marke:
Die aversiven Reize, die die Kaufentscheidung beeinflussen, sind:
Erwartungen, daß die Entscheidung für die ausgewählte Marke das zu tolerierende Risikopotential erhöht.
Erwartungen, daß die Marke nicht das bisher gewohnte Abwechslungspotential bietet.
Die verstärkenden Reize, die die Kaufentscheidung beeinflussen, sind:
Erwartungen, daß die Entscheidung für die Marke das Risikopotential vermindert oder ein drohendes Risikopotential nicht realisiert.
Erwartungen, daß die Marke ein angenehmes Abwechslungspotential bietet.
Die oben aufgeführten Reize sind solche, die im Rahmen einer kognitiven Lerntheorie das Entscheidungsverhalten erklären können. Die angesprochenen Erwartungen gründen vermutlich auf Lernprozessen, die auf Reiz-Reaktionsmechanismen zurückzuführen und schon vor der betrachteten Entscheidungssituation abgelaufen sind. In dem Moment, in dem die Marke gekauft und konsumiert wird, findet eine entsprechend den Eigenschaften der Marke gestaltete Verstärkung oder Bestrafung des Konsumenten für diese Entscheidung statt. Diese Erfahrung bedingt die Erwartungen, die der Konsument in einen erneuten Kauf der gleichen Marke setzt. Dies bedeutet, daß die Stimuluseigenschaften der konsumierten Marke einem stetigen Wandel unterworfen sind.
Meist liegen in einer Entscheidungssituation mehrere Alternativen vor, die in der Vergangenheit mehr oder weniger verstärkt wurden und deren Kauf mit entsprechenden Erwartungen verbunden ist. Der Konsument nimmt also schon kognitiv vorweg, welches Maß an Verstärkung er durch den Kauf dieser oder jener Marke erhalten wird. Die Auswahlwahrscheinlichkeit der verschiedenen Alternativen ergibt sich dann aus dem Gesetz des relativen Effekts.[3] Auf diesen Zusammenhang wird später in diesem Abschnitt noch genauer eingegangen. (siehe Kapitel: Gesetz des relativen Effekts)
[1] Präferenzen sind gleichbedeutend mit der Zuordnung von relativen Verstärkereigenschaften zu bestimmten Marken im Vergleich zu anderen Marken.
Weder das Risikopotential noch das Abwechslungspotential sind im Zeitablauf konstante Größen. Wie die Entwicklung von statten geht und wie die Verarbeitung der damit verbundenen Informationen erfolgt, soll kurz dargelegt werden.
Risikopotential und Erfahrung
Es gibt drei mögliche Bereiche, aus denen sich das Risikopotential ableiten läßt:
die Marke entspricht nicht den durchschnittlichen marktüblichen Qualitätsansprüchen und erfüllt deshalb nicht die Zielvorstellungen
die Marke erfüllt nicht die funktionellen Zielvorstellungen des Konsumenten, weil dieser sich nicht genau über seine Zielvorstellungen im klaren ist
die Qualität der Marke schwankt im Zeitablauf.
Wenn eine Marke zum ersten Mal gekauft wird, beinhaltet sie ein entsprechendes Risikopotential. Das bedeutet, daß die erste Kaufentscheidung mit einem großen Risikopotential verbunden ist. Sehr schnell, das heißt, entweder nach kurzem Gebrauch oder nach wenigen Käufen, wird der Konsument merken, ob die Marke in der Lage ist, die marktüblichen funktionellen Erwartungen zu erfüllen. Nach und nach wird der Konsument auch merken, ob die Marke die Bedürfnisse, die nach seiner Meinung eigentlich durch diese Produktkategorie abgedeckt werden sollten, auch wirklich befriedigt. Damit fällt auch dieses Risikopotential weg. Zurück bleibt die Ungewißheit über Qualitätsschwankungen.
Der im Rahmen der Risikoabschätzung ablaufende Informationsverarbeitungsprozeß dürfte zu komplex sein, um ihn mit Hilfe eines behavioristischen Ansatzes, also mit einfachen Reiz-Reaktionsmustern, zu interpretieren, da die Risikoempfindung meist auf einem umfangreichen Abwägungsprozeß beruht. Angemessener erscheint der kognitive Ansatz von Bruner.[1] Dieser Ansatz geht davon aus, daß alle Objekte und Ereignisse in Klassen eingeteilt werden. So würde die gekaufte Marke entsprechend des wahrgenommenen Risikos in eine bestimmte Risiko-Klasse eingeteilt. Wenn zusätzliche Erfahrungen durch Konsumtion gemacht werden, kann diese Kategorisierung noch geändert oder modifiziert werden. Nach und nach verfestigt sich die Einordnung in eine bestimmte Kategorie immer weiter.
Dieser Ansatz ist kompatibel zu den Annahmen, die zuvor über die Entwicklung des Risikopotentials im Zeitablauf gemacht wurden. So fällt die Ausschaltung des zuerst genannten Risikobereichs wohl noch in den Bereich des „cue search“ und damit einer „initial categorizing“. Wenn sich dann herausstellt, daß auch der zweite Risikobereich für die Marke nicht relevant ist, wird dadurch der von Bruner geforderte „confirmation check“ unterstützt und der Erwerb der Marke weiter als relativ risikolos eingestuft. In dem danach folgenden Stadium der „confirmation completion“ wird das endgültige Risikopotential der Marke durch eine Einordnung in eine bestimmte Klasse festgelegt. Da in diesem Stadium eine selektive oder überhaupt keine Informationsaufnahme mehr stattfindet, wird das Risikopotential aufgrund von Qualitätsschwankungen wohl gegen einen bestimmten Wert tendieren, der von der Häufigkeit von Qualitätsfehlern abhängig ist und sich nur sehr langsam ändert.
Die Kategorisierung wird also entweder im Rahmen einer „primitiven Kategorisierung“[2] ablaufen, wenn die ersten Erfahrungen mit der Marke die Risiken bestätigt oder aber entsprechend des oben dargestellten Ablaufs, wenn das Risiko nach und nach abgebaut wird. Im ersten Fall wird die Marke mit einem großen Risikopotential kategorisiert, im zweiten Fall wird die Marke nach einem aufwendigeren Kategorisierungsprozeß mit einem niedrigen Risikopotential eingestuft. Die Dauer des Kategorisierungsprozesses ist von der Komplexität des Produktes abhängig, da davon wiederum abhängig ist, wie schnell beurteilt werden kann, ob weitere Risiken bestehen oder nicht. Grundsätzlich kann man sagen, daß die Höhe des wahrgenommen Risikopotentials von der Erfahrung mit der Marke abhängig ist. Da die Häufigkeit des Wiederkaufs, das heißt die Erfahrung, von der Höhe der aversiven Reize, die mit der Marke verbunden sind, abhängig ist, wird mit großer Erfahrung tendenziell ein niedrigeres Risikopotential einhergehen.
Abwechslungspotential und Gewöhnung
Das Abwechslungspotential setzt sich aus verschiedenen Faktoren zusammen (Neuigkeitsaspekte, Ungewöhnlichkeit, Abwechslung usw). Grundsätzlich kann davon ausgegangen werden, daß der Mensch das Bedürfnis nach neuen und ungewöhnlichen Eindrücken hat. (siehe Kapitel 2.6.1.) Die Befriedigung dieses Bedürfnisses wird als positiv empfunden. Je neuer und ungewöhnlicher ein Reiz ist, desto angenehmer wird er tendenziell empfunden. Durch die analytische Trennung zwischen Risiko- und Abwechslungseigenschaften fallen erwartete Gefahren, die mit großer Neuartigkeit verbunden sein können, nicht in den Bereich des Abwechslungspotentials, sondern in den Bereich des Risikopotentials. Sicher gibt es eine Grenze, ab der eine weitere Steigerung der Ungewöhnlichkeit nicht angenehmer empfunden wird, dieser Fall soll jedoch außer Betracht bleiben. Kroeber-Riel geht davon aus, daß in der Konsumentenforschung der Scheitelpunkt, ab dem die Neuartigkeit als unangenehm empfunden wird, normalerweise nicht erreicht wird.[3]
Wenn eine Marke zum ersten Male gekauft wird, sind die wahrgenommene Neuartigkeit, die Ungewöhnlichkeit, die Komplexität etc. und damit ihre Verstärkereigenschaften am größten. Im Laufe des Konsums oder mehrerer Wiederkäufe steigt die Erfahrung, die der Konsument mit der Marke macht und führt zu einer Gewöhnung an die Eigenschaften der Marke. Der Konsument lernt, welche Eigenschaften die Marke hat. Damit nimmt die wahrgenommene Neuartigkeit, Ungewöhnlichkeit und Komplexität tendenziell ab. Dies bedeutet jedoch nichts anderes, als daß das Abwechslungspotential und damit die daraus abgeleiteten Verstärkereigenschaften der Marke abnehmen.
Auch bei der Erklärung der Entwicklung des Abwechslungspotentials kann die Theorie von Bruner hilfreich sein. Man kann nicht davon ausgehen, daß das Abwechslungspotential selbst das Objekt eines Kategorisierungsprozesses im Sinne von Brunner ist, da die Kategorisierung die Neuartigkeit zunichte machen würde. Vielmehr wird das Gefühl, inwieweit die Marke noch nicht kategorisiert ist, das Maß für das Abwechslungspotential sein. Je weiter die Kategorisierung fortgeschritten ist, desto geringer wird das Abwechslungspotential sein.
Eine Basisannahme der Dissonanztheorie besagt, daß die Dissonanzreduktionsbemühungen umso größer ausfallen, je stärker die perzipierte Dissonanz ist.
Über die bisher konsumierte Marke liegen bei der anstehenden Kaufentscheidung die meisten Informationen vor. Die möglichen Dissonanzen der anstehenden Kaufentscheidung können aufgrund der Erfahrungen in bezug auf diese Marke besser als bei noch nicht benutzten Marken eingeschätzt werden. Wenn die Erfahrungen mit der Marke bisher positiv waren, dann ist die Markentreue ein Mittel, die Dissonanz aus den antizipierten Folgen der Kaufentscheidung gering zu halten. Demgegenüber liegen über die Dissonanzen, die mit den alternativen Marken verbunden sind, nur Vermutungen vor. Prinzipiell sind alle Risiken möglich. Wenn die bisherigen Erfahrungen mit der aktuellen Marke eher negativ waren, kann es sein, daß eine neue Marke ausprobiert wird, weil die Dissonanz aufgrund der antizipierten Nachkaufdissonanz dadurch geringer ist als beim Kauf der schon bekannten Marke, bei der negative Konsequenzen sehr wahrscheinlich sind.
Aus der oben genannten Basisannahme kann abgeleitet werden, daß die Markentreue umso wahrscheinlicher ist, je größer die empfundene antizipierte Dissonanz für den Kauf der anderen Marken und je geringer sie bei der aktuellen Marke ist.
Ein weiterer Faktor, der für diese Untersuchung nur am Rande relevant ist, der aber auch die Markentreue aufgrund von Dissonanz verstärkt, ist folgender: Es konnte gezeigt werden, daß der Wiederkauf an sich eine Möglichkeit der Dissonanzreduktion ist. Durch die Wiederholung der Entscheidung versucht der Entscheidungsträger sich und der sozialen Umwelt zu beweisen, daß er richtig gehandelt hat.[1] Dieser Punkt wird bei der Darlegung des Risikos, in die Kategorie soziales oder psychologisches Risiko der Kaufentscheidung zu subsummieren sein.
Es konnte empirisch gezeigt werden, daß eine positive Korrelation zwischen der Stärke der empfundenen Dissonanz nach dem Kauf der Marke und der Wiederkaufwahrscheinlichkeit besteht.[2] Es ist allerdings zu beachten, daß diese Aussage nur für einen bestimmten Bereich der Dissonanz gilt. Wenn die Dissonanz zu groß wird, setzen gegenläufige Prozesse ein.
Dieser Zusammenhang ist wie folgt zu erklären. Je höher die kognitive Dissonanz nach der Kaufentscheidung ist, desto intensiver sind die daraufhin eingeleiteten Dissonanzreduktionsbemühungen. Eine Möglichkeit der Dissonanzreduktion ist eine kognitiv begründete Steigerung der Attraktivität der ausgewählten Alternative. Grundsätzlich wird die Steigerung der Attraktivität deshalb um so größer sein, je größer die kognitive Dissonanz zu Beginn war. Diese Aussage widerspricht dem gesunden Menschenverstand, ergibt sich jedoch aus der stringenten Anwendung der Theorie von Festinger.[3] In der Realität wird es vermutlich so sein, daß bis zu einem gewissen Grad eine Steigerung der Attraktivität stattfindet. Wenn die Dissonanz zu groß wird, müssen entweder andere Dissonanzreduktionsmethoden angewendet werden oder es findet eine Abwendung vom Stimulus statt.
„Consumers are subject to limitations in processing capacity. This means that detailed and complex calculations or comparisons among alternatives may be the exeption rather than the rule. Consumers may often use simple heuristics to make comparisons. These heuristics allow adaptation to the potentially complex choices consumers must make.“[1]
Im Mittelpunkt dieser Untersuchung steht eine Entscheidungssituation. Eine Entscheidung setzt die Auswahlmöglichkeit zwischen mehreren Alternativen voraus. Bevor eine sinnvolle Entscheidung zwischen diesen getroffen werden kann, die nicht nur vom Zufall abhängig ist, müssen Informationen über die Alternativen aufgenommen und verarbeitet werden. Selbst die Entscheidung zwischen zwei alternativen Handlungsmöglichkeiten, die sich stark unterscheiden, bei denen also die eine besonders vorteilhaft und die andere besonders unvorteilhaft erscheint, erfordert ein Minimum an Informationsverarbeitung. Je mehr Alternativen in der Entscheidungssituation relevant sind und je ähnlicher diese bezüglich der relevanten Entscheidungskriterien wahrgenommen werden, desto aufwendiger ist der Informationsverarbeitungsprozeß. Ein weiterer Faktor, der das Ausmaß der erforderlichen Informationsbeschaffungs- und Informationsverarbeitungsmaßnahmen bedingt, ist das Maß an Sicherheit, das der Konsument im Augenblick der Entscheidung haben möchte, um die optimale Alternative auszuwählen.[2] In der Kaufentscheidungssituation kann der Konsument jederzeit die Kaufentscheidung treffen. Je nachdem wieviel Informationen er vor der Entscheidung beschafft und verarbeitet hat, ist es dann mehr oder weniger so, daß er die Entscheidung trifft, bevor alle möglichen Charakteristiken des Produktes verglichen wurden. Dadurch riskiert der Konsument, einen Fehler zu machen, indem er bezüglich bestimmter Charakteristika des Produktes nicht die optimale Entscheidung trifft oder einen trade-off Prozeß nicht abgeschlossen hat. Der Konsument wird deshalb genauso lange die relevanten Alternativen bezüglich ihrer Charakteristika vergleichen, bis er den von ihm verlangten Sicherheitslevel erreicht hat.
Da die Informationsverarbeitungskapazität des Menschen begrenzt ist und die Auswahlentscheidung meist unter einem gewissen Zeitdruck getroffen werden muß, ist der Konsument darauf angewiesen, seine Informationsverarbeitungskapazitäten möglichst ökonomisch einzusetzen, um in der zur Verfügung stehenden Zeit den angestrebten Sicherheitslevel zu erreichen. Je größer die Sicherheitsansprüche sind, desto größer sind die kognitiven Belastungen, weil in vorgegebener Zeit mehr Informationen verarbeitet werden müssen. Wenn von Kosten der Verarbeitung gesprochen wird, sind damit sämtliche Anstrengungen gemeint, die der Konsument auf sich nehmen muß, um den persönlichen Sicherheitslevel zu erreichen, bei dem er bereit ist eine Entscheidung zu treffen. Im Mittelpunkt des Interesses stehen die kognitiven Aktivitäten.
Hansen geht darauf ein, inwieweit der vom Konsumenten angestrebte Sicherheitslevel tatsächlich erreicht oder statt dessen eine Zwischenlösung angestrebt wird:
„If for a moment the attention is fixed on a problem, wether a solution will be found depends on the tolerable level of conflict. If this level is high, the choice process may terminate with a ‚commitment‘ to a solution that still is quite conflicting and does not resolve the complex cognitive structure by which the problem is represented. In such a case elements of the problem can be neglected and a semi-solution can be established, but the conflict is likely to be rearoused. If, however, the tolerable amount of conflict is low, a considerable higher degree of consistency is required before a solution is deemed acceptable, which increases the likelyhood that the problem really is solved.“[3]
Dieses Zitat wirft eine weitere Frage auf: Verändert sich die Motivation, eine befriedigende Entscheidung zu treffen und damit die Motivation zur Informationsverarbeitung im Laufe des Informationsverarbeitungsprozesses, also mit abnehmendem Konflikt?
Die Entscheidungssituation stellt den Konsumenten vor ein Informationsverarbeitungsproblem. Es gibt bestimmte Ziele, die durch die Entscheidung erreicht werden sollen und es existiert ein bestimmtes Maß an Unsicherheit, ob einzelne Produkte diese Ziele erfüllen. Gleichzeitig steht der Konsument unter Zeitdruck. Er wird Schritte einleiten, um die Unsicherheit zu reduzieren und in der vorgegebenen Zeit zu einer Entscheidung zu gelangen. Es gibt verschiedene Meinungen dazu, wie sich das Bedürfnis nach Information auf dem Weg bis zum angestrebten Sicherheitslevel entwickelt. Es geht also um folgende Frage: Verändert sich das Bedürfnis nach Information vom Beginn des Entscheidungsprozesses bis hin zu dem Punkt, wo der Sicherheitslevel erreicht wird? Das Bedürfnis nach Information sollte logischerweise genauso stark sein wie das Bedürfnis, den Sicherheitslevel zu erreichen, da es sich hieraus ableitet. Das Bedürfnis, diesen Sicherheitslevel zu erreichen, ist nichts anderes als das Konsistenzmotiv oder das Motiv nach Risikoreduktion, da es sich bei der Situation um eine inkonsistente oder eine Risikosituation handelt. Eine ungewisse Situation ist inkonsistent, weil die Anforderungen an eine zufriedenstellende Entscheidung nicht mit der empfundenen Entscheidungssituation übereinstimmen. Der akzeptierte Unsicherheitslevel ist nichts anderes als das gerade noch akzeptierte Maß an Inkonsistenz oder der Risikotoleranzlevel, wobei bei den letzten beiden die Bedeutung der Situation noch eine Rolle spielt. Eine größere Unsicherheit wird als inkonsistent empfunden, weil sie nicht mit den Sicherheitsansprüchen übereinstimmt. Verstärkt wird das Konsistenzmotiv durch Informationen, die den inkonsistenten Zustand in einen konsistenten überführen. Durch Informationsaufnahme steigt die Vertrautheit mit der Situation oder dem Produkt und damit wird die Inkonsistenz der Situation abgebaut.
Howard fordert in seiner Theorie des Kaufentscheidungsverhaltens, die auf den Zusammenhang zwischen Produktvertrautheit und quantitativer Informationsbeschaffung eingeht, daß der Informationsbedarf mit zunehmender Vertrautheit mit dem Produkt und dem Markt abnimmt.[4] Das bedeutet im Rückschluß, daß mit abnehmender Inkonsistenz, also je näher der angestrebte Sicherheitslevel rückt, die Neigung diese Inkonsistenz abzubauen, abnimmt.
Bettman und Park fordern dagegen einen Verlauf, der einer umgekehrten U-Kurve entspricht. Sie kommen zu der Überzeugung, daß Konsumenten mit mittlerer Produktvertrautheit informationsverarbeitungswilliger sind, während wenig und sehr vertraute Konsumenten dazu neigen, Beurteilungsaufgaben zu vereinfachen. Sie verlassen sich auf solche Merkmale, die als „chunks“ bezeichnet wurden.[5]
Insgesamt herrscht in der Literatur Uneinigkeit darüber, ob eine große Vertrautheit zu einem gesteigerten oder zu einem reduzierten Informationsbedarf führt und ob mittelmäßig vertraute Personen, wie Bettman und Park dies fordern, eher in der Lage sind, Informationen zu verarbeiten, als die beiden anderen Gruppen.
Bettman[6] stellt fest, daß die Wahrscheinlichkeit einer intensiven kognitiven Beschäftigung mit den Alternativen von zwei Faktoren abhängig ist, nämlich von der Motivation, dies zu tun und von der Fähigkeit, sich mit diesen Daten auseinandersetzen zu können. Er konnte in seiner Studie feststellen, daß die Wahrscheinlichkeit, sich intensiv mit den Alternativen auseinanderzusetzen, bei einem mittleren Maß an Erfahrung mit der Marke am größten ist. Bei geringerer oder größerer Erfahrung ist diese Bereitschaft, also mehr kognitive Energie zu investieren, geringer. Im ersten Moment erscheint dieses Ergebnis den Erkenntnissen der Theorien des Such- und Entdeckungsverhaltens zu widersprechen. Diese fordern, daß vor allem im unteren und im oberen Bereich der Vertrautheit das SEV zu beobachten ist. Trotzdem sind die Ergebnisse kompatibel. Bei zu geringer Gewöhnung äußert sich das SEV durch Markentreue und der Beschäftigung mit der Marke an sich. Der kognitive Aufwand ist entsprechend gering. Bei zu großer Gewöhnung setzt auch SEV ein. Dies äußert sich im Fall der Theorien des SEVs im Zusammenhang mit der Kaufentscheidung zum Beispiel durch Markenwechsel. Für Bettman ist der Punkt der großen Erfahrung mit der Marke jedoch nicht dort, wo schon eine Sättigung eingesetzt hat. Das heißt, andere Marken werden noch nicht in Erwägung gezogen. Demnach betrachtet Bettman bei seiner Untersuchung nur den Bereich bis zum optimalen Punkt der Theorien des SEV. Der Punkt, den Bettman den Punkt mit großer Erfahrung nennt, liegt ungefähr im optimalen Aktivierungslevel, in dem aufgrund der Zufriedenheit die kognitive Aktivität gering ist.
Des weiteren ist die quantitative Nutzung von Informationen abhängig von der Anzahl der verfügbaren Merkmale. Mit steigender Anzahl verfügbarer Merkmale nimmt die Anzahl genutzter Informationen zwar zu, gemessen an der insgesamt zur Verfügung stehenden Informationsmenge jedoch ab.[7]
Wie schon angedeutet wurde, ist reine Informationsverarbeitung nicht die einzige Möglichkeit, die Unsicherheit zu reduzieren. Es gibt andere Strategien, die ebenfalls in der Lage sind dies zu erreichen und zwar mit geringeren Verarbeitungskosten. Shugan führt drei Möglichkeiten an: „The cost of thinking can be reduced by (1) memory, (2) summary statistics, and (3) probabilistic sampling.“[8] Der erste Punkt macht sich im Rahmen des Kaufentscheidungsprozesses zum Beipiel durch Markentreue bemerkbar. Auch die Entscheidung für die Markentreue muß, wie schon ausgeführt, nicht zwangsläufig ohne jegliche Informationsverarbeitung abzulaufen. Bettman[9] stellt insgesamt zehn verschiedene Auswahlheuristiken zusammen (z.B.: konjunktive, disjunktive, lexikografische usw.). Eine der dargestellten Heuristiken ist die „affekt referral“-Heuristik. „In affect referral, a consumer does not examine attributes or beliefs about alternatives, but simply elicits from memory a previously formed overall evaluation for each alternative. Thus the evaluation process is wholistic.“[10] Bei dieser Auswahlheuristik werden nicht einzelne Attribute des Produktes, sondern die mit der Alternative verbundenen Affekte miteinander verglichen. Das Auswahlkriterium ist der Maximierungsgrundsatz, das heißt, die Alternative, die mit dem angenehmsten Affekt verbunden ist, wird ausgewählt. Dies scheint die angemessene Auswahlheuristik zu sein, um den Entscheidungsprozeß bei Markentreue zu betrachten. Dieser Auswahlprozeß ist in der Lage, sehr komplexe Auswahlentscheidungen auf ein Minimum an kognitiver Anstrengung zu reduzieren. Der zweite Punkt von Shugan kann als die Hinzuziehung von Urteilen, die auf den durchschnittlichen Urteilen einer breiten Mehrheit beruhen, interpretiert werden. Ein gutes Beispiel ist die Entscheidungsunterstützung durch die Zeitschrift „test“, die bei ihren Urteilen allgemein anerkannte Wertmaßstäbe zugrunde legt. Wenn die dritte Option angewendet wird, bedeutet dies, daß nur eine begrenzte Anzahl von Attributen der Marken verglichen werden. Dabei wird mit großer Wahrscheinlichkeit davon ausgegangen, daß sich von der Ausprägung dieser Attribute auf die gesamte Eignung der Marke schließen läßt.
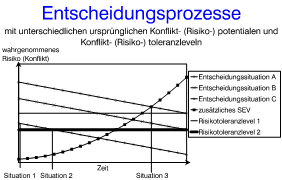
Zu jedem Zeitpunkt, des Produktauswahlprozesses, existieren zwei Handlungsalternativen. Die erste Alternative besteht in der Auswahl des aktuell am attraktivsten erscheinenden Produktes. Die zweite Alternative besteht darin, weitere Überlegungen und Informationsbeschaffung zu betreiben. Wenn man in einem Koordinatensystem die Zeit auf der Abszisse und den wahrgenommenen Konflikt auf der Ordinate darstellt, bildet die erste Handlungsalternative eine fallende Kurve und die zweite Handlungsalternative eine steigende Kurve. Je nachdem, wie in der Entscheidungssituation das ursprüngliche Risikopotential war und wie hoch der Risikotoleranzlevel liegt, sind verschiedene Situationen vorstellbar (siehe Abb. 4). Wenn in Situation 1 davon ausgegangen wird, daß der Risikotoleranzlevel 1 gilt, dann kann bezogen auf Entscheidungssituation C die Entscheidung ohne jedes weitere SEV getroffen werden. Wenn in der gleichen Entscheidungssituation allerdings Risikotoleranzlevel 2 gilt, dann muß in gewissem Maße SEV durchgeführt werden, bis das wahrgenommene Risiko gleich dem Risikotoleranzlevel ist (Situation 2). In der Entscheidungssituation A wird zwar nach langer Zeit auch irgendwann der Risikotoleranzlevel erreicht, vorher ist jedoch der wahrgenommene Konflikt durch zusätzliches SEV so groß, daß dieser sogar den Konflikt durch das noch bestehende Risiko bei einer unmittelbaren Entscheidung übertrifft (Situation 3). Wenn der Konflikt aufgrund des wahrgenommenen Risikos gleich dem Konflikt aufgrund zusätzlichen SEV ist, dann wird die Entscheidung getroffen.[11] Abb. 4 (Entscheidungsprozeß)
Die Menge der notwendigen kognitiven Energie für die Informationsverarbeitung ist von dem wahrgenommenen Risiko und der aufgrund dessen ausgewählten Auswahlheuristik[12] abhängig. „Consumer spend different amounts of energy on various choices, and these differences must be explained in terms of varying amounts of motivation at the time of the choice.“[13] Hansen schlägt vor, daß ein U-förmiger Zusammenhang zwischen dem Konflikt und der Komplexität des Auswahlprozesses besteht. Die geringste Komplexität liegt dann vor, wenn der Punkt des tolerierbaren Konfliktes erreicht ist. Mehr oder weniger Konflikt erfordern komplexere Auswahlprozesse, entweder auf der Suche nach Stimulation oder beim Problemlösen. Allerdings steigt die Komplexität der Problemlösungsprozesse nicht monoton an. Vielmehr wird davon ausgegangen, daß Vermeidungsverhalten auftritt und das Komplexitätsniveau spontan reduziert wird, wenn der wahrgenommene Konflikt ein bestimmtes Niveau übersteigt.[14]
Wir verwenden Cookies, um unsere Website und unseren Service zu optimieren.
Einige sind notwendig, damit diese Website funktioniert. Andere helfen uns den Service weiter zu verbessern. Wir empfehlen, alle Cookies zu akzeptieren.
Notwendige Cookies
Immer aktiv
Die technische Speicherung oder der Zugang ist unbedingt erforderlich für den rechtmäßigen Zweck, die Nutzung eines bestimmten Dienstes zu ermöglichen, der vom Teilnehmer oder Nutzer ausdrücklich gewünscht wird, oder für den alleinigen Zweck, die Übertragung einer Nachricht über ein elektronisches Kommunikationsnetz durchzuführen.
Vorlieben
Die technische Speicherung oder der Zugriff ist für den rechtmäßigen Zweck der Speicherung von Präferenzen erforderlich, die nicht vom Abonnenten oder Benutzer angefordert wurden.
Statistiken
Die technische Speicherung oder der Zugriff, der ausschließlich zu statistischen Zwecken erfolgt.Die technische Speicherung oder der Zugriff, der ausschließlich zu anonymen statistischen Zwecken verwendet wird. Ohne eine Vorladung, die freiwillige Zustimmung deines Internetdienstanbieters oder zusätzliche Aufzeichnungen von Dritten können die zu diesem Zweck gespeicherten oder abgerufenen Informationen allein in der Regel nicht dazu verwendet werden, dich zu identifizieren.
Marketing
Die technische Speicherung oder der Zugriff ist erforderlich, um Nutzerprofile zu erstellen, um Werbung zu versenden oder um den Nutzer auf einer Website oder über mehrere Websites hinweg zu ähnlichen Marketingzwecken zu verfolgen.